generation is a loop
Why LLMs can't plan, why they feel slow, and why 'thinking' is just buying time.
When you use an LLM, the words don’t appear all at once. They stream in, one by one, like a ghost is typing on the other side of the screen.
To a user, this feels like “thinking”. But to an engineer, this stream is the raw exposure of a mechanical constraint. It is the visual proof that the “Assistant” doesn’t have a plan.
In the first post, we established that an LLM is a document completion engine. You give it a manuscript (the prompt), and it writes what comes next.
But how does it write?
The answer explains everything from why models can’t solve math problems instantly, to why “jailbreaks” work, to why streaming APIs look the way they do.
The Autoregressive Loop
The core mechanic of a large language model is the autoregressive loop.
It works like this:
- Input: You feed the model a sequence of tokens (the context).
- Forward Pass: The model runs these tokens through its layers once.
- Probabilities: It outputs a probability score for every possible next token in its vocabulary.
- Sample: It selects the next token based on these probabilities and your settings (like temperature). It’s essentially rolling a weighted die.
- Append: It adds that new token to the end of the sequence.
- Repeat: It feeds the new, slightly longer sequence back into Step 1.
- Stop: It stops when it hits a stop token or runs out of tokens, and returns the final sequence to the client.
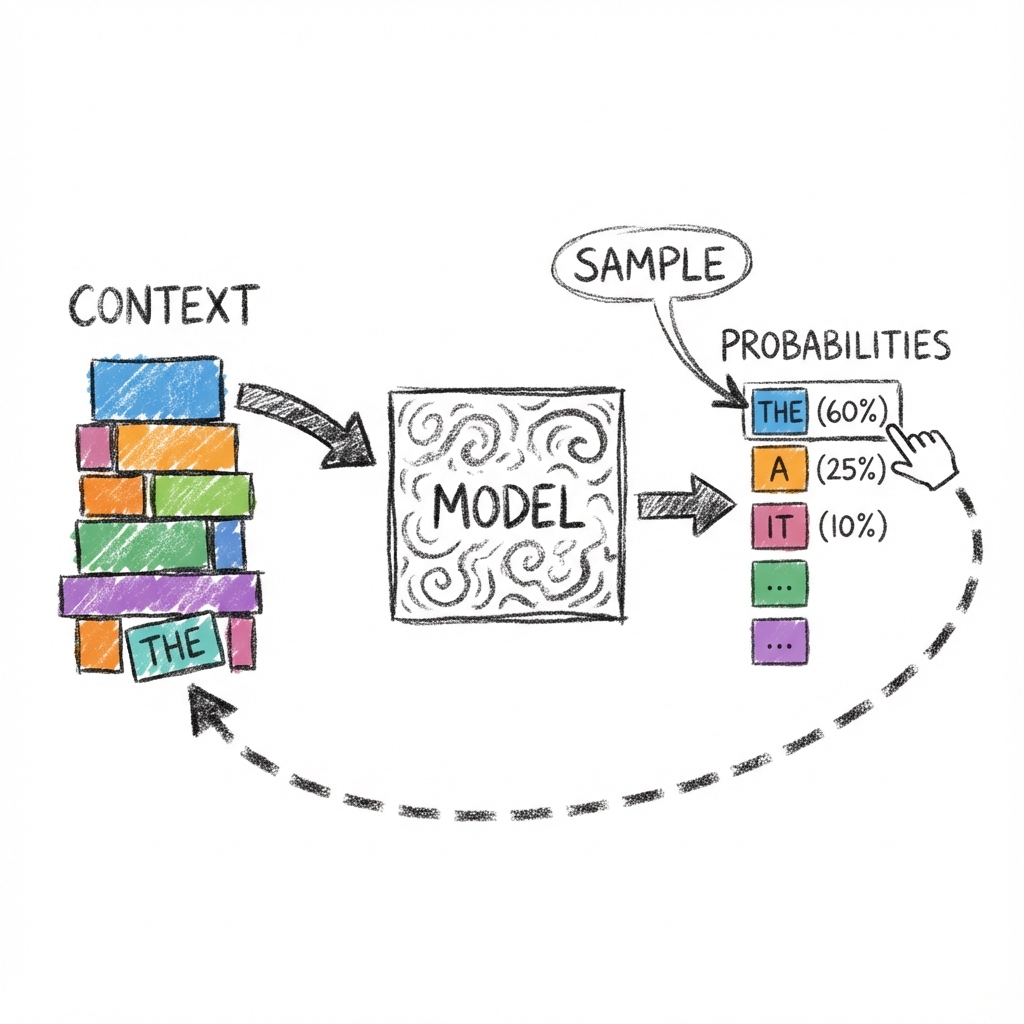
This loop is rigid. The model cannot produce two tokens at once. It cannot “skip ahead” to write the end of the sentence. To generate a 100 token paragraph, the model must run the loop 100 times, sequentially.
No Secret Thoughts
Because of this loop, we arrive at the most critical insight for building reliable agents:
If the model hasn’t generated the token, it hasn’t thought about it.
Humans have a separate “buffer” for thinking. You can pause, formulate a complex sentence in your head, check if it’s offensive, rephrase it, and then speak it.
LLMs do not. The output is the thought process. They are thinking out loud, one token at a time.
It is improvising its way through the document, token by token. If it writes “The answer is”, it has committed to providing an answer right now. It cannot pause to calculate.
Chain of Thought is Just “Buying Compute”
This explains why chain of thought (CoT) works.
If you ask: “What is 482 * 194?”
- Zero-shot: The model has 1 forward pass to output the answer. It has to memorize the multiplication table for these specific numbers. It usually fails.
- Chain of Thought: “Let’s calculate step by step. 400 * 100 is 40000…”
By forcing the model to write out the steps, you are forcing it to run the loop more times
. You are buying it more “forward passes” (more compute) and letting it dump its intermediate state into the context window so it can “read” its own work for the next step.
The Loop and Latency
The autoregressive loop also explains why APIs stream.
When you use a “blocking” API (waiting 5 seconds for the whole reply), you are looking at a lie. The provider’s server isn’t thinking for 5 seconds and then handing you a result. It is frantically running the generation loop, buffering the new tokens in memory, and only sending the full text to you when it hits a stop token.
Streaming is the raw exposure of the machine’s autoregressive loop.When you see a token stream, you are seeing the loop execute in real-time. This is why the chunks usually look like this:
// Raw SSE Event from OpenAIdata: { "id": "chatcmpl-123", "choices": [ { "index": 0, "delta": { "content": " world" }, "finish_reason": null } ]}The model literally cannot compute the 10th word until the 9th word exists.
The “slowness” you feel isn’t just network latency. It is physical dependency.
Conclusion
The “Chat” interface disguises a specialized document completion engine. This engine doesn’t have a brain that pauses to think. It has a loop that must keep spinning.
If you want your agent to be smarter, you don’t need a better prompt “commander.” You need to give the loop enough room to spin and generate the tokens that represent the thinking, before it commits to an answer.
In the next post, we’ll talk about the context window: the model’s only form of short-term memory, and why “context” is much more than just the words you type.